Passare dal database SQL Oracle al NoSQL: la giusta scelta per performance fino a 20 volte migliori
La modalità di archiviazione e capacità di gestione dei dati digitali risulta essere, quanto mai prima d’oggi, di fondamentale importanza per qualsiasi tipologia di attività e business. Ciò nonostante, non sembra ancora esser chiaro quali siano le migliori tecnologie ed i migliori strumenti per far sì che i dati vengano utilizzati e sfruttati al meglio. All’interno di questo articolo, vi mostreremo quelle che sono le principali differenze esistenti tra I tradizionali DB relazionali e i DB NoSQL, i vantaggi derivanti dall’utilizzo di quest’ultimo e, più nello specifico, le straordinarie performance del Database Non Relazionale Apache Cassandra.
DATABASE RELAZIONALI e NON RELAZIONALI: DIFFERENZE
Cominciamo col dire che la differenza principale esistente tra un DB SQL tradizionale come quello sviluppato da Oracle e DB NoSQL come Apache Cassandra risiede proprio nella loro diversa strutturazione tecnica e nel tipo di linguaggio utilizzato per la creazione ed esecuzione di query.
Un Database Relazionale o SQL (con riferimento appunto al linguaggio impostato per la scrittura di query – structured query language) risulta avere una struttura basata sul concetto di relazione. Le relazioni, o tabelle, sono organizzate in celle, raggruppate a loro volta in righe e colonne. Il rapporto che si viene a creare tra relazioni e colonne è denominato schema: all’interno del DB Relazionale, lo schema deve essere settato e definito prima dell’aggiunta di dati.
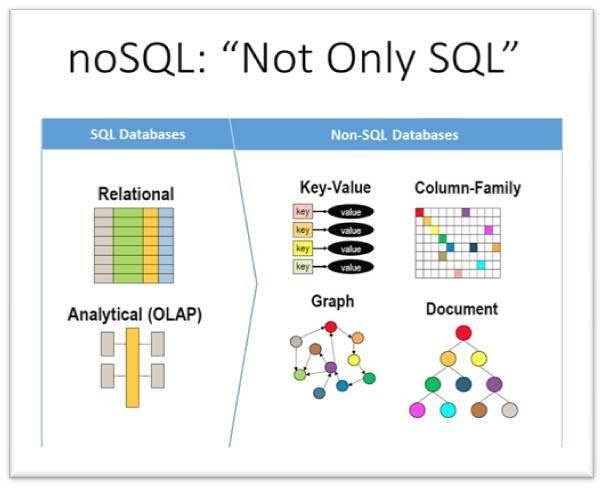
La definizione “NoSQL” (Not Only SQL), al contrario, implica che questa tipologia di Database non necessariamente deve utilizzare il linguaggio SQL e dunque maggiore libertà generale. il flusso delle operazioni risulta essere privo di vincoli: non vi sono schemi predefiniti.
Essendo nati proprio per rispondere ad esigenze di flessibilità, I DB NoSQL possono avere strutture tecniche differenti: nello specifico, vi sono 3 principali strutture possibili. I NoSQL possono essere document-oriented, con una rappresentazione dei dati in strutture simili ad oggetti, o anche di tipo “key/value”, e quindi presentare una struttura a dizionari e mappe. Il meccanismo di questa tipologia prevede l’inserimento di una chiave per l’estrazione veloce di un valore e di un valore appunto ad essa associato, che a sua volta contiene l’informazione. Altro tipo di struttura per DB NoSQL è quella a grafo, basata su rete di nodi collegati attraverso archi.
Fonte: Medium
Ancora, vi sono tipologie di DB NoSQL “ibridi”, quali ad esempio Apache Cassandra.
Cassandra è un ampio archivio di colonne e, come tale, è essenzialmente un ibrido tra un sistema Key/Value ed un sistema a tabelle. Il suo modello di dati consiste in un archivio di righe partizionato con consistenza accordabile. Quest’ultimo concetto è un’estensione di quello di consistenza, che fa riferimento al livello di aggiornamento e sincronizzazione di una riga di una tabella Cassandra in tutte le sue repliche. Attraverso la consistenza accordabile, per ogni operazione di scrittura o lettura, il client può decidere il livello di consistenza che vuole raggiungere. In Cassandra dunque, grazie all’utilizzo della consistenza accordabile, è possibile scegliere un livello di consistenza “strong” o “eventual” a seconda delle proprie necessità: questo ha molta importanza all’interno di un sistema distribuito, in cui più copie dello stesso set di dati risiedono su server fisici diversi nel sistema. Si può anche decidere di fare un mix dei due tipi di consistenza, e dunque utilizzare il tipo “strong” per un centro dati locale (dove la latenza può avere 1 ms) ed il tipo “eventual” per un centro dati remoto (dove la latenza potrebbe essere 100 ms o più).
Ritornando alla struttura di Cassandra, le righe sono organizzate secondo tabelle; il primo componente della chiave primaria di una tabella rappresenta la chiave della partizione; all’interno di una partizione, le righe sono raggruppate dalle colonne restanti della chiave. Altre colonne possono essere indicizzate separatamente rispetto la chiave primaria.
Le tabelle possono essere create, rilasciate e modificate durante l’esecuzione senza necessità di bloccare aggiornamenti e l’esecuzione di queries.
All’interno di Cassandra, si enfatizza la denormalizzazione attraverso caratteristiche come le collezioni.
Con la denormalizzazione, è possibile ottimizzare la performance in lettura del DB, aggiungendo ridondanza ai dati o raggruppandoli.
L’operazione di denormalizzazione viene utilizzata dunque proprio per risolvere l’inefficienza dei sistemi relazionali: la velocità di risposta del DB a una data query e più in generale il miglioramento di performance in lettura è oggi sicuramente più importante rispetto all’organizzazione dei dati stessi.
Una famiglia di colonne (chiamata “tabella”) ricorda una tabella di un DB Relazionale. Le famiglie di colonne contengono righe e colonne. Ogni riga viene identificata in modo univoco da una chiave di riga. Ogni riga ha più colonne, caratterizzate da nome, valore e timestamp. A differenza di una tabella in un Database Relazionale, righe diverse nella stessa famiglia di colonne non devono necessariamente condividere lo stesso insieme di colonne, e una colonna può essere aggiunta a una o più righe.
Ogni chiave in Cassandra rappresenta un valore che è un oggetto. Ogni chiave ha dei valori come colonne, e le colonne sono raggruppate in gruppi denominati famiglie di colonne. In questo modo, ciascuna chiave identifica una riga di un numero variabile di elementi. Queste famiglie di colonne possono essere considerate tabelle. Una tavola in Cassandra è una mappa multidimensionale distribuita indicizzata da un tasto. Ancora, le applicazioni possono specificare l’ordine delle colonne all’interno di una super colonna o anche di una famiglia di colonne semplici.
Scopri la nostra consulenza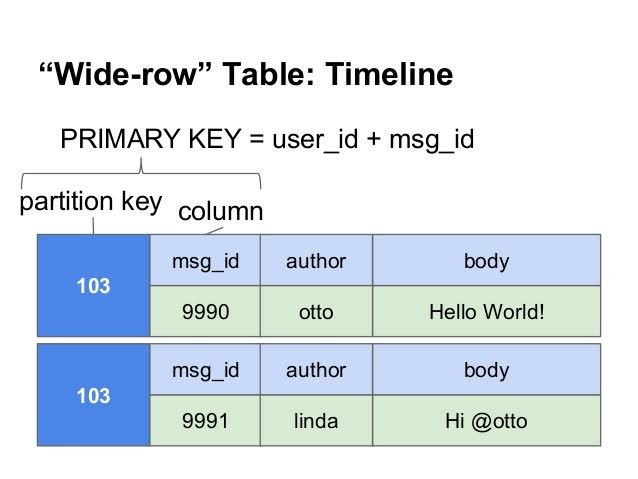
Fonte: Slideshare
La seconda, sostanziale, differenza tra DB NoSQL e Database SQL risiede nella modalità di memorizzazione e gestione del dato.
Nel caso dei DB Relazionali, i dati devono risultare essere strutturati e organizzati prima della loro importazione.
Al contrario, nel caso dei DB NoSQL, i dati non devono obbligatoriamente essere strutturati prima dell’importazione all’interno del DB. I DB NoSQL eliminano il problema delle limitazioni riguardanti relazioni rigorose: vi sono vari modi per memorizzare e gestire i dati. Attraverso l’utilizzo di un DB NoSQL, si può creare un numero illimitato di voci, o viceversa, soluzioni molto semplici ma estremamente efficaci. Le informazioni non trovano più posto in righe elencate in tabelle, ma in oggetti completamente diversi e non necessariamente strutturati.
I DB NoSQL sono semplici da scalare sia verticalmente (come i DB Relazionali) che orizzontalmente: rispetto al DB Relazionale, il Non Relazionale permette dunque la creazione di cluster formato da più macchine, garantendo una migliore e più equa distribuzione dei dati e, al tempo stesso, grande affidabilità.
PERCHÉ PASSARE DA UN DB SQL AD UNO NoSQL
Molte delle tecnologie più importanti ed incisive presenti oggi sul mercato per migliorare il proprio business producono quantità massiva di dati di tipo non strutturato: sensori IoT, dati provenienti da social networks, foto, video, informazioni riguardanti la localizzazione, attività online, applicazioni web, metriche e tanto altro. Se si considera che moltissime aziende hanno costruito la propria fortuna attraverso l’analisi e la comprensione di questo tipo di dati, risulta difficile pensare che un DB SQL possa essere oggi ancora sufficiente. I DB NoSQL sono nati proprio per rispondere alle esigenze di flessibilità e scalabilità, caratteristiche non presenti all’interno dei DB SQL.
I vantaggi dell’effettuare questo importante cambio sono molteplici e sostanziali. Nonostante la migrazione dei dati verso un DB NoSQL possa risultare, a prima vista, un’attività troppo complessa e onerosa, la verità è che le tecnologie di oggi permettono di effettuare il tutto in poco tempo e nel modo più semplice possibile. Ma soprattutto, bisogna porre l’attenzione sui benefici che si otterranno una volta effettuata la migrazione, in termini di velocità e performance.
Le informazioni che circolano al giorno d’oggi in rete sono tantissime, e si presentano sotto molteplici forme e dimensioni: dinanzi ad un simile scenario, l’opzione di dover rendere ogni dato strutturato e dunque importabile all’interno di un DB relazionale sembra essere difficile da prendere in considerazione.
Vediamo, qui di seguito, alcuni vantaggi tecnici legati all’utilizzo di un Database NoSQL.
- Operazioni computazionali più semplici: Non effettuando aggregazioni sui dati, i DB Non Relazionali non hanno problemi legati al peso computazionale.
- Nessuno schema: i Database NoSQL sono privi di schema e non vi è necessità di definizione. In questo modo, si possono arricchire le applicazioni di nuovi dati e informazioni, definibili liberamente all’interno del DB NoSQL senza correre rischi sull’integrità dei dati. I Database Non Relazionali, a differenza di quelli SQL, si dimostrano quindi adatti a inglobare velocemente nuovi tipi di dati e a conservare dati semistrutturati o non strutturati.
- Scalabilità: l’aggregazione dei dati e l’assenza di uno schema definito a priori offre l’opportunità di scalare orizzontalmente senza difficoltà e senza rischi operativi.
- Accelerare il time to market: i Database NoSQL garantiscono velocità di operazione e di analisi, e dunque permettono di elaborare i dati nel minor tempo possibile, di modo da poter intervenire tempestivamente sulle proprie strategie di business.
- Facilità di accesso: le basi di dati NoSQL offrono un altro vantaggio importante, specialmente per coloro i quali sviluppano app: facilità di accesso. I Database Relazionali hanno una relazione densa con applicazioni scritte in linguaggi orientati ad oggetti quali Java, php e Python. I NoSQL permettono spesso di scavalcare il problema attraverso l’utilizzo di API, per l’esecuzione di queries senza la necessità di conoscere il linguaggio SQL.
CASI DI SUCCESSO NoSQL: I BIG CHE HANNO SCELTO CASSANDRA
Grandi colossi come Facebook, Netflix e Twitter utilizzano Database NoSQL per gestire i i propri dati. Questa scelta è stata effettuata per garantire velocità di esecuzione anche nell’elaborazione di terabyte e terabyte di dati, scalabilità orizzontale, un elevato livello di availability e la possibilità di contenere migliaia di dati non strutturati senza bisogno di settare uno schema fisso.
Tra i “Big” che hanno scelto di effettuare il passaggio al NoSQL (e nello specifico ad Apache Cassandra) troviamo Facebook, che oltre ad aver contribuito allo sviluppo del codice di questo DB, ha deciso di utilizzarlo per potenziare la ricerca all’interno del sistema di posta. Digg, importantissimo sito di social news, utilizza Cassandra dal 2010. Twitter, altro famosissimo social network, è passato a Cassandra per rispondere all’esigenza di eseguire operazioni su diversi cluster e server. Un altro colosso dei nostri giorni, Netflix, utilizza Cassandra per gestire al meglio i dati dei propri sottoscrittori.

Nello specifico, Netflix ha dichiarato di aver deciso di usare Cassandra NoSQL perché questa tipologia di Database può scalare orizzontalmente e dinamicamente con l’aggiunta di più server, senza la necessità di fermare i servizi, quindi a caldo. L’assenza di limiti riguardanti la scalabilità, di limitazioni architettoniche su dimensione di dati, conteggi di righe e colonne ecc. e le ottime prestazioni soprattutto per ciò che concerne il throughput di scrittura hanno fatto sì che Netflix decidesse di adottare questa tecnologia per il proprio business.
Alcune delle caratteristiche più attraenti di Cassandra, a detta di Netflix, sono la sua coerenza flessibile e i modelli di replica. Le applicazioni possono determinare a livello di chiamata il livello di coerenza da utilizzare per le letture e le Scritture (singole, quorum o per tutte le repliche). Questo, insieme con la feature di fattore di replica personalizzabile, e il supporto speciale per determinare i nodi del cluster da designare come repliche, lo rende particolarmente adatto per le distribuzioni cross-datacenter e interregionali. In effetti, un singolo cluster Cassandra globale può servire in modo simultaneo le applicazioni e replicare in modo asincrono i dati in più posizioni geografiche. Cassandra è dunque secondo Netflix la migliore tecnologia per la distribuzione cross-regionale e il ridimensionamento senza singoli points of failure.
TEST DI PERFORMANCE SU CASSANDRA NoSQL
Isaac ha scelto di costruire la propria piattaforma sulle basi del Database NoSQL Apache Cassandra a seguito di un approfondito scouting su tutte le migliori tecnologie Non Relazionali presenti oggi sul mercato. La scelta è stata motivata dai requisiti unici di tale Database, tra i quali figurano:
1. Alta disponibilità. Cassandra non presenta point of failure, tutti i nodi del cluster sono identici. La perdita di un singolo nodo non impedisce le operazioni di scrittura/lettura.
2. Scalabilità in scrittura. Cassandra con il suo modello a “master multipli” può scrivere da qualunque nodo. Se aumenta il carico di lavoro, è sufficiente aggiungere un nodo a caldo (senza interruzione del servizio) per scalare il carico.
3. Supporto di un query language. A differenza di altri Database NoSQL, Cassandra supporto il CQL, un linguaggio molto simile a quello SQL che permette l’analisi dei dati.